 陈用饼的博客
陈用饼的博客 
基本组件
- LLM:Qwen3-4B
- 视觉编码器:CLIP-ViT-Large-Patch14-336
- 投影器:两层全连接层,使用 GeLU 激活
- 数据集:LLaVA-CC3M-Pretrain-595K
基本流程
- 从 HuggingFace 下载模型与数据集,并在 Qwen 的模型目录下的分词配置文件
tokenizer_config.json中增加<image>作为图像 token 的占位符。 - 使用
transformers中的AutoModelForCausalLM、AutoTokenizer、AutoProcessor、CLIPVisionModel组件加载模型。 Dataloader 实现细节:
1) labels 相对于 inputs 不用右移一位,因为 transformers 加载的 LLM 默认会自动移位。
2) labels 中的 human_input 部分使用 ignore_token 填充,不参与 loss 计算。
3) 一个 batch 中,labels 和 inputs 的长度使用 pad_token 补齐到该 batch 中的最长序列长度。
4) pad_token 不参与注意力计算;ignore_token 不参与 loss 计算。训练细节:
1) 预训练阶段冻结 ViT 和 Qwen,仅激活投影层。
2) 为节省显存,采用Accelerator的混合精度训练。
3) 设置epoch=1,batch_size=1,每 16 个 step 累积梯度后更新,防止梯度波动过大。
4) 每 1000 个 step 保存一次最佳 loss 的权重。
5) 最终在 2 张 32GB 的 GPU 上训练约 22 小时,成本约为 74 元。
训练结果
模型可以正确识别大多数简单图像的内容:
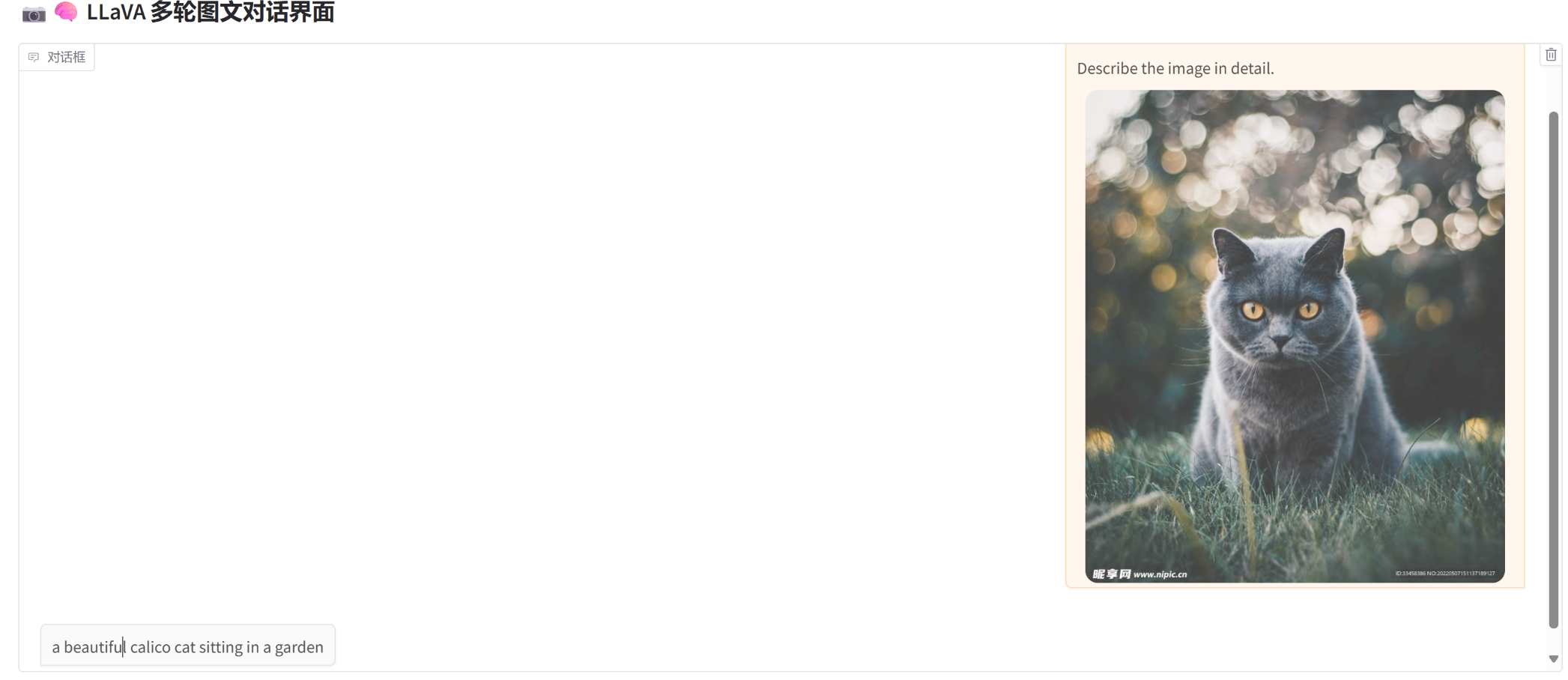
未经微调的情况下,仅能输出简短图像描述,prompt 提示无效,无法进行多轮对话。
可能原因包括:
- 投影层映射出的视觉 token 中隐含“简短回答”的倾向(因预训练文本都较简短);
- 视觉 token 数量过多(577 个),在整体输入中占比太高,导致 prompt 的控制力被削弱。
因此,后续微调阶段应激活投影层参数进行调优。
思考
视觉 token 数量太多,导致 LLM 的计算复杂度较高(O(N²·d)),而其中只有部分是有效信息。可考虑:
1) 对视觉 token 进行压缩(如 CLIP-ViT 中的 token pooling、token selection)
2) 加入视觉注意力裁剪策略- 数据过于单一,可考虑增加控制回答长短的指令,如
请详细描述图像内容、简洁回答等,增强模型响应多样性。 - 预训练阶段,图像 token 映射后的特征不仅包含纯图像语义,可能混杂“回答风格”等伪语义。
如果将训练目标改为文本描述的 embedding 向量,且 仅使用 LLM 的 embedding 层与视觉投影层进行训练,可能具有如下优点:
1) 降低训练成本
2) 减少幻觉
3) 更适配视觉理解任务
延伸
多模态视觉token压缩
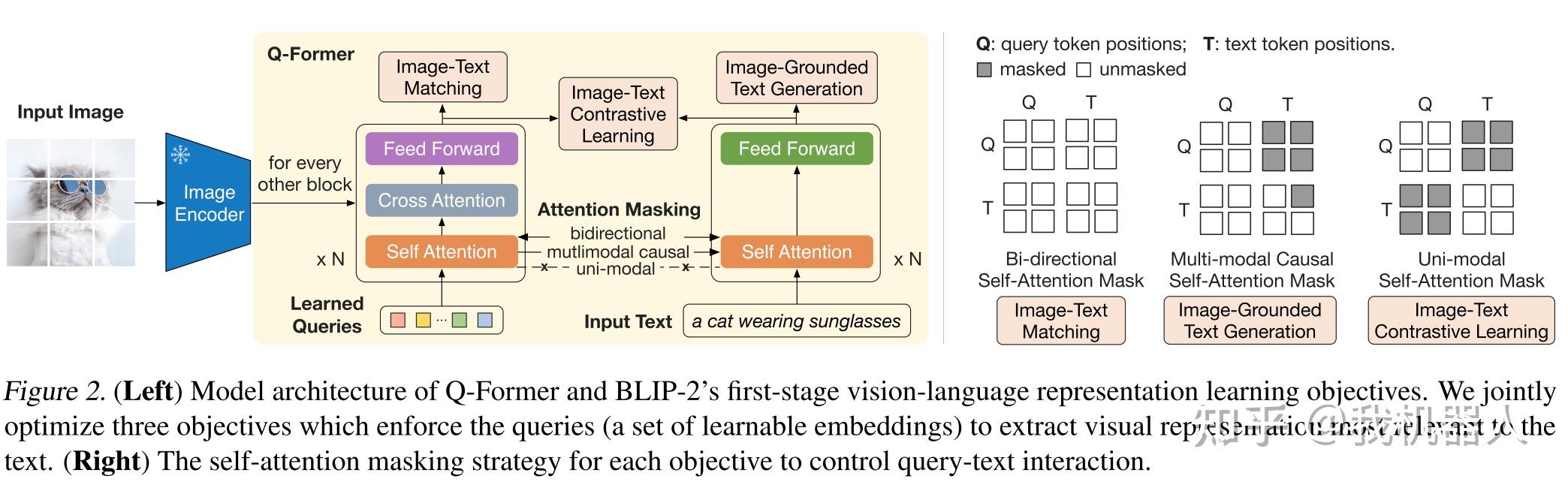
- Q-Former
Q-Former通过引入固定数量(一般为32)的query,与图像token做交叉注意力计算,引导图像特征的提取,最终得到32个token,远远少于LLaVA中的577个,大大减少LLM中的计算量。![Q-Former]()
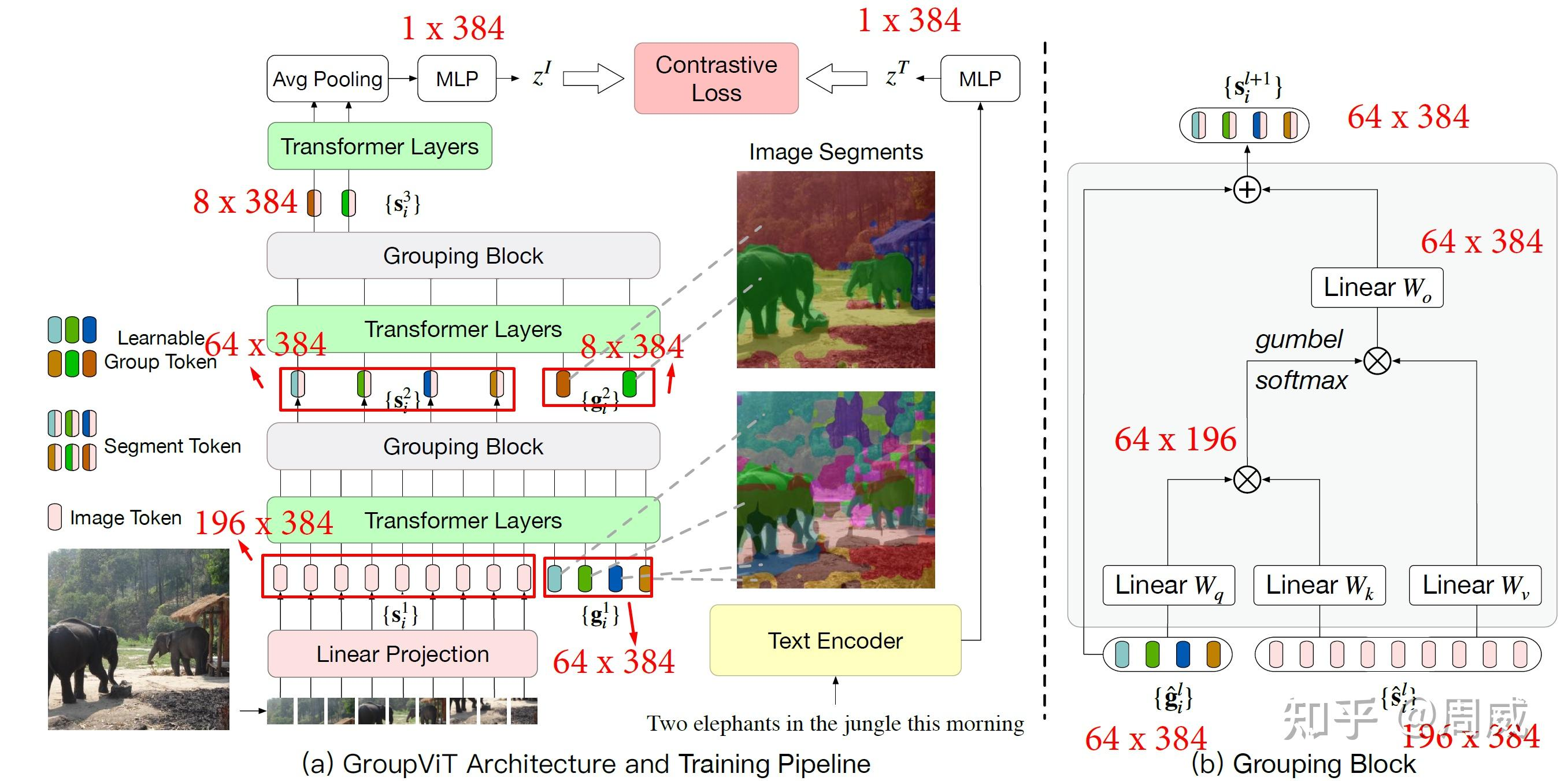
附:如果把Q-Former中的query换做输入LLM的指令,用于指导特征的提取,是不是可以通过语言引导视觉特征的提取。或许适用于语义分割或者目标检测。类似的的有Group-Vit,但是这里的query也是固定数量的,通过与文本的对比来确定类别。![Group-Vit]()
FocusLLaVA中的图像引导采样器
1) 局部区域划分(局部建模)
将全局特征图按窗口大小划分为多个局部特征块:X₀, X₁, ..., X_{M−1},每个区域单独进行尺度选择,避免全局统一尺度带来的信息损失。2) 使用MoE 机制进行尺度选择(专家选择)
将不同尺度的下采样器视为多个专家。 对每个Xi与全局特征进行相关性评分,选择最合适的专家,进行token压缩。- FastVLM
FastVLM中计算视觉token中每个token与'[CLS]'token的注意力权重(相关性),过滤掉低相关性的token,剩下的token与文本token拼接送入LLM。
结果:
在仅仅保留了5%的token,没有任何额外训练的情况下,在10个任务中保持91.5%的原始性能。
LLaVA复现笔记

https://t.me/s/pt1win/256
2025年10月新盘 做第一批吃螃蟹的人coinsrore.com
新车新盘 嘎嘎稳 嘎嘎靠谱coinsrore.com
新车首发,新的一年,只带想赚米的人coinsrore.com
新盘 上车集合 留下 我要发发 立马进裙coinsrore.com
做了几十年的项目 我总结了最好的一个盘(纯干货)coinsrore.com
新车上路,只带前10个人coinsrore.com
新盘首开 新盘首开 征召客户!!!coinsrore.com
新项目准备上线,寻找志同道合 的合作伙伴coinsrore.com
新车即将上线 真正的项目,期待你的参与coinsrore.com
新盘新项目,不再等待,现在就是最佳上车机会!coinsrore.com
新盘新盘 这个月刚上新盘 新车第一个吃螃蟹!coinsrore.com
https://t.me/pt1win/109
2025年10月新盘 做第一批吃螃蟹的人coinsrore.com
新车新盘 嘎嘎稳 嘎嘎靠谱coinsrore.com
新车首发,新的一年,只带想赚米的人coinsrore.com
新盘 上车集合 留下 我要发发 立马进裙coinsrore.com
做了几十年的项目 我总结了最好的一个盘(纯干货)coinsrore.com
新车上路,只带前10个人coinsrore.com
新盘首开 新盘首开 征召客户!!!coinsrore.com
新项目准备上线,寻找志同道合 的合作伙伴coinsrore.com
新车即将上线 真正的项目,期待你的参与coinsrore.com
新盘新项目,不再等待,现在就是最佳上车机会!coinsrore.com
新盘新盘 这个月刚上新盘 新车第一个吃螃蟹!coinsrore.com
2025年10月新盘 做第一批吃螃蟹的人coinsrore.com
新车新盘 嘎嘎稳 嘎嘎靠谱coinsrore.com
新车首发,新的一年,只带想赚米的人coinsrore.com
新盘 上车集合 留下 我要发发 立马进裙coinsrore.com
做了几十年的项目 我总结了最好的一个盘(纯干货)coinsrore.com
新车上路,只带前10个人coinsrore.com
新盘首开 新盘首开 征召客户!!!coinsrore.com
新项目准备上线,寻找志同道合 的合作伙伴coinsrore.com
新车即将上线 真正的项目,期待你的参与coinsrore.com
新盘新项目,不再等待,现在就是最佳上车机会!coinsrore.com
新盘新盘 这个月刚上新盘 新车第一个吃螃蟹!coinsrore.com
https://t.me/pt1win/42
新盘 上车集合 留下 我要发发 立马进裙
2025年10月新盘 做第一批吃螃蟹的人coinsrore.com